
函数的第二次作业
1 例6-18
1.1 分析
见下方1.2 代码实现,可以看到课本实现时使用了Python的内置函数zip():分别将原始字符串和用户输入的字符串中的每一个字符打包成了一个个元组,最后在比较时的是这些元组返回的每一对字符。
然而我们不妨查阅《Python官方文档》上对应的解释(以下只截取部分解释),来看看在使用该函数时还需要注意哪些情况: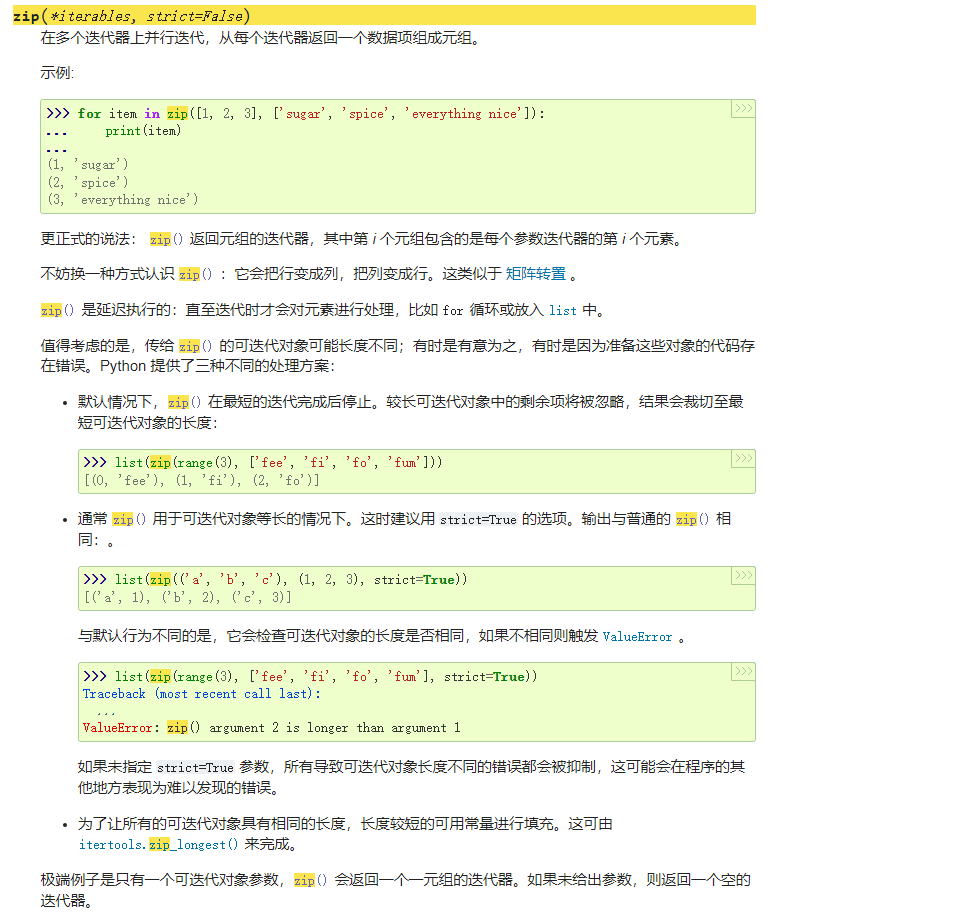
也就是说,在本题中当两个字符串进行匹配时zip()函数帮我们将最长的字符串裁剪至了最短字符串的长度。
因而,如果我们不比较字符串的长度,两个字符串最后的匹配结果可能是100%,但是存在这两个字符串并不一致的情况。
该情况演示如下: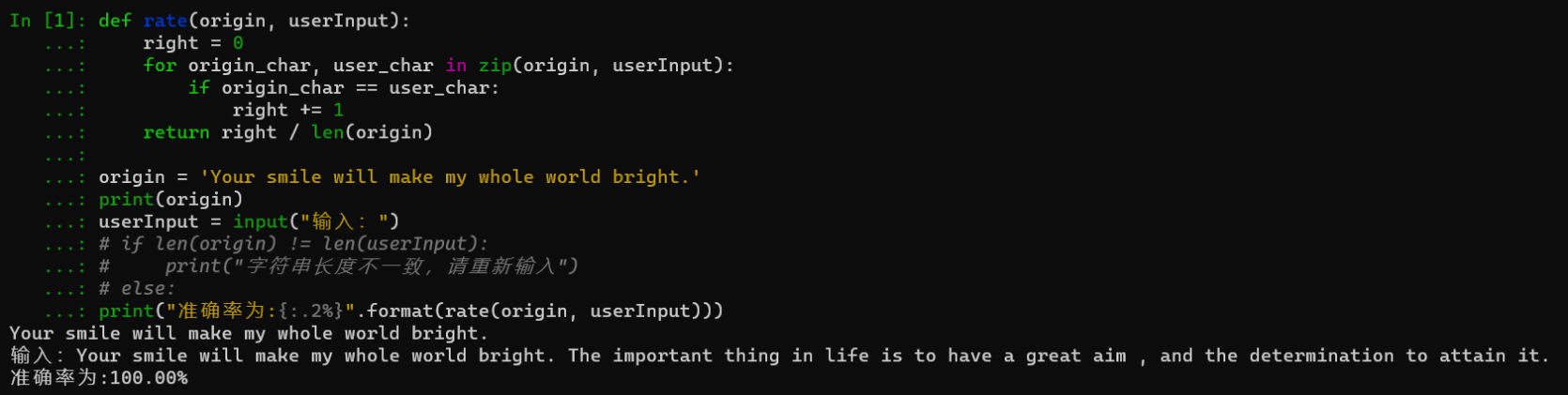
1.2 代码实现
def rate(origin, userInput):
right = 0
for origin_char, user_char in zip(origin, userInput):
if origin_char == user_char:
right +=1
return right/len(origin)
origin = 'Your smile will make my whole world and bright.'
print(origin)
userInput = input("输入:")
if len(origin) != len(userInput):
print("字符串长度不一致,请重新输入")
else:
print("准确率为:{:.2%}".format(rate(origin, userInput)))Your smile will make my whole world and bright.
准确率为:100.00%2 例6-19
2.1 分析
见2.2 代码实现的注释
2.2 代码实现
def getText(text):
text = text.lower() # 将文本中的字母统一为小写
for ch in ",.?-:\'":
text = text.replace(ch, " ") # 将文本中的标点替换为空格
return text
def wordFreg(text, topn):
words = text.split() # 分割出每个单词
counts = {}
for word in words:
# get()方法在统计单词出现频率中很常用,如果在字典中存在就在原计数上+1,否则就计数为1
counts[word] = counts.get(word, 0) + 1
excludes = {'the', 'and', 'to', 'of', 'a', 'be'}
for word in excludes:
del(counts[word]) # 删除excludes中的单词
items = list(counts.items()) # sort()方法是针对列表的,因此我们将其变成列表
items.sort(key = lambda x:x[1], reverse = True)
return items[:topn]
text = '''I have a dream today!I have a dream that one day every valley shall be exalted, every hill and mountain shall be made low, the rough places will be made plain, and the crooked places will be made straight; "and the glory of the Lord shall be revealed, and all flesh shall see it together."
This is our hope. This is the faith that I go back to the South with. With this faith we will be able to hew out of the mountain of despair a stone of hope. With this faith we will be able to transform the jangling discords of our nation into a beautiful symphony of brotherhood. With this faith we will be able to work together, to pray together, to struggle together, to go to jail together, to stand up for freedom together, knowing that we will be free one day.'''
text = getText(text)
for word, freq in wordFreg(text, 20):
print("{:<10}{:>}".format(word, freq))
print("统计结束")will 6
together 6
this 5
shall 4
faith 4
with 4
we 4
that 3
made 3
able 3
i 2
have 2
dream 2
one 2
day 2
every 2
mountain 2
places 2
is 2
our 2
统计结束3 实验指导p58第7题
3.1 分析
书上的方法已经写的很详细了,没有需要另外补充的,因此以下对书上的方法进行简述:
先将正整数num转换为字符串s
1. 方法一:将字符串遍历时的每个字符转换为数字进行累加。
2. 方法二:使用列表函数sum()将通过列表生成器生成的由各位数字的字符作为元素组成的列表进行求和。
3. 方法三:思路同方法二,这次使用的是map()函数来代替列表生成器帮助我们将字符串s转换为列表。
3.2 代码实现
3.2.1 方法一
def add(num):
sum = 0
# 将数字转换为字符串
s = str(num)
for i in s:
sum += int(i)
return sum
num = int(input("请输入一个正整数:"))
if num < 0:
print("输入有误")
else:
print("各位数字之和为:",add(num))请输入一个正整数:452
各位数字之和为: 113.2.2 方法二
def add(num):
# s = str(num)
# ls = [int(c) for c in s]
# return ls
return sum([int(c) for c in str(num)])
num = int(input("请输入一个正整数:"))
if num < 0:
print("输入有误")
else:
print("各位数字之和为:",add(num))请输入一个正整数:54321
各位数字之和为: 15以上代码函数部分可以简写成一行,如下:
def add(num):
return sum([int(c) for c in str(num)])因此,我们可以想到lambda表达式!
num = int(input("请输入一个正整数:"))
if num < 0:
print("输入有误")
else:
print("各位数字之和为:",(lambda num: sum([int(c) for c in str(num)]))(num))请输入一个正整数:12345
各位数字之和为: 153.2.3 方法三
def add(num):
s = str(num)
return sum(map(int, s))
num = int(input("请输入一个正整数:"))
if num < 0:
print("输入有误")
else:
print("各位数字之和为:",add(num))请输入一个正整数:5678
各位数字之和为: 26同上3.2.2 方法二,这里也可以使用lambda表达式:
num = int(input("请输入一个正整数:"))
# f = lambda num: sum(map(int, str(num)))
if num < 0:
print("输入有误")
else:
# print("各位数字之和为:",f(num))
print("各位数字之和为:", (lambda num: sum(map(int, str(num))))(num))请输入一个正整数:8765
各位数字之和为: 264 实验指导p58第11题
4.1 分析
同样书上的方法已经写的很详细了,另外之前的作业也有这道题,因此简述一下即可:
1. 方法一:下一项为item*10+a(item为当前项数值,a为参数)。
2. 方法二:将数字a转换为字符串str(a),可以利用字符串乘法的特性,下一项为int(str(a))*n(n为当前第n项,规定n>0)。
4.2 代码实现
4.2.1 方法一
def sum(a, n):
s = 0
for i in range(1, n + 1):
s += int(str(a) * i)
print("s={}".format(s))
a = int(input("请输入一个1-9之间的某个数字a:"))
n = int(input("请输入一个正整数n:"))
sum(a, n)请输入一个1-9之间的某个数字a:6
请输入一个正整数n:10
s=74074074004.2.2 方法二
def sum(a, n):
s = 0
item = 0
for i in range(1, n + 1):
item = item * 10 + a
s += item
print("s={}".format(s))
a = int(input("请输入一个1-9之间的某个数字a:"))
n = int(input("请输入一个正整数n:"))
sum(a, n)请输入一个1-9之间的某个数字a:6
请输入一个正整数n:10
s=74074074005 实验指导p58第17题
5.1 思路分析
这题比较有意思,除了课本中所提示的通过比较ASCII码大小的方式来判断是否包含数字和字母以外,还有几种方法:
1. 既然是针对字符串,既然我们使用的是拥有庞大类库的Python语言。那么首先应该想到是否有相关的内置函数或方法。str.islower()可以帮助我们判断是否存在小写字母,str.isupper()可以用于判断是否存在大写字母,str.isdigit()可以判断是否存在数字。
如果题目还要求数字和密码混合输入或者判断密码是否包含字母,我们同样有str.isalnum()和str.isalpha来帮助我们。(Python官方文档的对其相关说明贴在了5.3 Python文档相关补充,见下)
2. 另外,既然是判断字符也可以通过使用运算符in来判断该字符是否在a~z组成的字符串中从而得知其是否为小写字母。同理,判断小写字母与数字也可如法炮制。(实现分别见5.2 代码实现的第7、13、19行。)
最后,再来回答书中提出的问题,为什么在循环中需要使用break?
我们不妨假设判断密码是否有数字时不使用break的情况:如果该密码有n个数字(规定n>0),那么密码强度就会增加n级。这很明显与题意密码包含数字则密码强度增加一级不符。
5.2 代码实现
def judge(password):
strength = 0
if len(password) < 8:
strength += 1
for i in password:
# if i.islower():
# if i in 'abcdefghijklmnopqrstuvwxyz':
if 'a' <= i <= 'z':
strength += 1
break
for i in password:
# if i.isupper():
# if i in "ABCDEFGHIJKLMNOPQRSTUVWXYZ":
if 'A' <= i <= 'Z':
strength += 1
break
for i in password:
# if i.isdigit():
# if i in '0123456789':
# if 0 < int(i) < 10:
if '0' <= i <= '9':
strength += 1
break
if strength == 1:
print("密码强度为1级")
elif strength == 2:
print("密码强度为2级")
elif strength == 3:
print("密码强度为3级")
elif strength == 4:
print("密码强度为4级")
else:
print("密码强度为0级")
password = input("请输入密码:")
judge(password)
请输入密码:15dreS
密码强度为4级5.3 Python文档相关补充




6 反思与复盘
在完成这个作业的过程中,我的效率有些过于低下了,为此展开了反思。
限时完成,提高效率
首先应该给自己限时,如果在这个时间内没能完成这个to do list,那么就不要再做了,直接丢掉然后去做其它的学习任务。毕竟如果从作业布置开始的那一天开始距离ddl还有很长的时间。这样也可以增强自己在做题时的紧迫感,而不至于思绪经常溜号,以及交叉学习也能让自己不会长时间卡在思维定势里。
其次在做题的时候可以先把框架打出来,先预览所有要去做的题然后列下能立刻想到的思路(这个时间绝对不会花太长,千万不要懒得去做),这样会让自己之后做题顺畅很多。
不要急,慢慢来
如果没有思路,那就应该先勇于承认自己在这一块知识没有掌握好。不要着急,先将题目大致预览一遍,写下自己的思路和卡在了哪些地方(当然这个过程同样是需要限时的),列出几个关键词后再看看课本的相关知识先复习,不要着急去写。因为如果急着去做题而不是复习,自己常常会陷入焦虑之中,这个时候往往会产生厌学从而逃离焦虑反而距离作业渐行渐远。
完成永远大于完美
完成永远大于完美。如果代码没能实现或者有报错不要担心,无论是对所学的掌握还是动力,都是在行动之中逐渐获得与积累的,而绝不是在犹豫彷徨与胆怯不自信中进步的。所以要直接开始去做,
另外永远不要相信一劳永逸这个词,不要认为自己作业第一次做就可以达到完美也不要认为自己写了一次作业就可以完全掌握了。无论是代码的运行还是对关联知识的理解都是在不断运用不断修改中体会和领悟到的,而不是一次就可以达到醍醐灌顶的效果。
信念
无论是面对代码报错还是在使用Pycharm或者Jupyter甚至是在未来的任何事情上出现了问题,都要有一种信念,那就是:它一定会被我解决!如果还没有解决,就只能说明是付出的时间不够。
这个作业从开始到完成一共用了两天的时间,在这期间出现过Jupyter连接服务器失败,出现过代码突然无法在Jupyter中运行了,以及lambda函数的使用异常还有各种代码报错甚至电脑绿屏。但是我带着我一定会解决这些问题、这些问题都只是暂时的的信念,最后将它们逐一解决掉了。这些问题被解决后,也让我对这些知识有了更深刻的理解。因此,也希望在将来,如果我再遇到报错或者其它问题,我也要带着这样的信念去面对它们!
总结
最后总结:限时(记录ddl)+计时、保持专注(手机关机)、不要急慢慢来(先花几分钟预览要做什么,将大致思路以及要做哪些的框架还有卡在哪里了都逐一写下来;不必要求自己在一个时间段内完成,可以分几次来完成——第一次预览并记录下思路和卡在了哪里,第二次去复习解决掉自己的问题,第三次再来正式写作业,最后再完善与修改它们。)
最后的最后总结:学习就是不断制作“预习——学——复习”的to do list和在ddl前完成to do list的过程,放在作业里也同样:作业是制作“预先浏览并记录下相关思路及疑问——正式去写——修改、完善、总结复盘和重做作业的内容”的to do list和完成的过程。
最后给自己留下一个问题,Python的函数部分会考哪些呢,站在出题者的角度,如果是我出题我会怎么出?这将作为我复习的重点!
 微信
微信- 支付宝

